1. مقدمه
یادگیری عمیق (Deep Learning) شاخه ای از بحث یادگیری ماشینی و مجموعه ای از الگوریتم هایی است که تلاش می کنند مفاهیم انتزاعی سطح بالا را با استفاده یادگیری در سطوح و لایه های مختلف مدل کنند . یادگیری عمیق در واقع نگرشی جدید به ایده شبکه های عصبی می باشد که سالیان زیادی است وجود داشته و هر چند سال یکبار در قالبی جدید خود را نشان می دهد.
1.1 شبکه عصبی
تعاریف مختلفی برای یادگیری عمیق وجود دارد که همه ی آن ها در یک نکته مشترک هستند.ابتدا به معرفی نورون ها و شبکه های عصبی میپردازیم و سپس یادگیری عمیق را معرفی خواهیم کرد.
-
سلول عصبی مصنوعی : توافق دقیقی بر تعریف شبکه عصبی در میان محققان وجود ندارد اما اغلب آن ها موافقند که شبکه عصبی شامل شبکه ای از عناصر پردازش ساده (نورونها) است، که می تواند رفتار پیچیده کلی تعیین شده ای از ارتباط بین عناصر پردازش و پارامترهای عنصر را نمایش دهد.
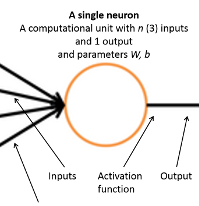
تصویر 1 – مدل تک نورون عصبی مصنوعی
در تصویر ۱ مدل یک نورون عصبی مصنوعی را مشاهده می کنید که از بخش های ورودی ، تابع فعال ساز و خروجی تشکیل شده است. خروجی تابع فعال ساز یک شب از رابطه ی زیر بدست می آید.
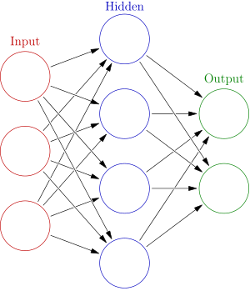
تصویر 2 – ساختار شبکه عصبی ساده
تا اینجا با یک نورون عصبی آشنا شدیم و این که چگونه به ورودی ها حساسیت نشان می دهد و خروجی خود را به وسیله تابع فعال سازی را ایجاد می کند. حال تصور کنید مجموعه ای از این نورون ها در کنار هم قرار بگیرند و یک شبکه را تشکیل بدهند. ساختاری مشابه با تصویر-۲ را در نظر بگیرید یک لایه ی ورودی ، یک یا چندین لایه مخفی داخلی و یک لایه خروجی . با کنار هم قرار گرفتن این نورون های واحد چه در جهت عمودی (کنار هم) و چه در جهت افقی (روی هم) شکل خواهند گرفت و در نهایت با یک لایه خروجی پایان خواهند یافت .
لایه اول ورودی های شبکه را فراهم می کند و خروجی خود را به لایه های مخفی داخلی می دهد . لایه بعدی بسته به نحوه اتصال لایه قبلی به ورودی خود و وزن های هر اتصال خروجی خود رو محاسبه می کند و به لایه بعدی ارسال می کند. در نهایت لایه پایانی وظیفه دارد با توجه به ورودی های خود خروجی تولید شده را به مقیاس مطلوب ببرد. یک نوع متداول از لایه های خروجی با استفاده از تابع SIGMOID و SOFTMAX ساخته می شود.
تابع sigmoid هر عدد طبیعی را به بازه ی [۱و۰] نگاشت خواهد کرد لذا تابع فعال سازی می تواند به عنوان احتمال برای آن واحد عصبی در نظر گرفته شود. پس برای m نورون عصبی که مشابه تصویر-۲ قرار گرفته اند با استفاده از نوشتار ماتریسی خواهیم داشت :
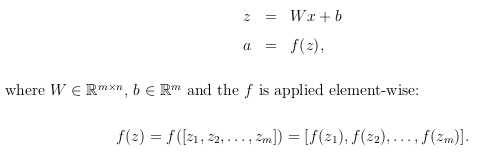
تعریف ماتریسی برای شبکه ای از m نورون
حال در صورت لزوم میتوان لایه ای دیگری در مقابل این لایه اضافه کنیم و یا مستقیما خروجی را محاسبه نماییم. توجه نمایید که این تنها یکی از حالت های ساخت یک شبکه عصبی بود و انواع مختلف دیگری موجود دارد که کاربردهای دیگری دارند، مزایا و معایب گوناگونی دارند و هریک در کاربرد خاصی بهتر جواب می دهند . تصویر-۲ یک شبکه از نوع FeedFoward یا پیشخور را نشان می دهد که در آن جهت جریان اطلاعات از ورودی به خروجی و همواره در یک جهت است . ورودی های هر لایه از لایه ما قبل می آید و هر نورون در لایه های مخفی به ورودی های تولید شده توسط لایه قبلی واکنش نشان می دهد .نوع دیگری از شبکه های عصبی وجود دارد که RNN یا بازگشتی (Recurrent Neural Network) نامیده می شود. در این نوع شبکه هر لایه ی مخفی ممکن است از خروجی خود بازخورد بگیرد و نسبت به خروجی خود نیز واکنش نشان بدهد . برای اطلاعات بیشتر به می توانید به کتاب های شبکه های عصبی از جمله کتاب طراحی شبکه های عصبی نوشته مارتین هاگان، مقدمه ای بر شبکه عصبی نوشته لوران فاست، شبکه عصبی نوشته دکتر محمد باقر منهاج مراجعه بفرمایید.
مزایا و معایب: ایده شبکه های عصبی بیش از ۶۰ سال است که مطرح شده است. ثابت می شود با کمک شبکه های عصبی هر تابعی قابل محاسبه می باشد و استفاده خاص آن بیشتر برای مواردی است که تقریب های خطی به کار نمی آیند. در این حالت ها می توان با ساختن یک تابع غیر خطی خروجی های قابل قبولی را تولید کرد .این ویژگی باعث می شود برای حل کردن مسائل در زندگی واقعی مناسب باشند و در این مسائل کاربرد داشته باشند. این شبکه ها می توانند توسط روش های با ناظر (Supervised Learning) ، بدون نظارت (Unsupervised Learning) و تقویتی (Reinforcement Learning) آموزش داده شوند .
واقعیت این است که استفاده از این شبکه ها جز در موارد خاص بسیار هزینه بر و مشکل است. دلایل آن را می توان در موارد مختلفی جست و جو کرد. از پیچیدگی های آموزش دادن و کمبود منابع سخت افرازی می توان نام برد . حتی با پیشرفت های کنونی در زمینه سخت افزار هنوز هم برای تامین منابع کافی روی یک ماشین مشکل وجود دارد و باید از روش های پردازش توزیعی به عنوان راه حل استفاده کرد.
1.2 یادگیری عمیق
یادگیری عمیق شاخه ای از بحث یادگیری ماشینی و مجموعه ای از الگوریتم هایی است که تلاش می کنند مفاهیم انتزاعی سطح بالا را با استفاده یادگیری در سطوح و لایه های مختلف مدل کنند. یادگیری عمیق در واقع نگرشی جدید به ایده شبکه های عصبی می باشد که سالیان زیادی است وجود داشته و هر چند سال یکبار در قالبی جدید خود را نشان می دهد. روشن کردن این نکته ضروری به نظر می رسد که شبکه های عصبی یک لایه مخفی درونی دارند و شبکه ای که چندین لایه ی مخفی درونی داشته باشد شبکه عمیق نامیده می شود. دو مزیت این شیوه یادگیری در زیر آمده است.
- بازنمایی یادگیری: نیاز اصلی هر الگوریتم یادگیری ویژگی هایی است که از ورودی ها استخراج می شود . ممکن است این ویژگی ها از پیش به صورت دستی تهیه شده و به الگوریتم خورانده شود که این روش در الگوریتم های با ناظر به کار می رود . در مقابل روش های بدون نظارت خواهد بود که خود اقدام به استخراج ویژگی ها از ورودی خواهد نمود. استخراج دستی ویژگی ها علاوه بر اینکه زمانبر است معمولا هم ناقص و در عین حال بیش از حد نیازِ ذکر شده می باشد. یادگیری عمقی برای ما یک راه استخراج خودکار ویژگی ها پدید می آورد.
-
یادگیری چندین لایه بازنمایی ها: یادگیری عمقی برای ما این امکان را به وجود می آورد که بتوانیم که مفاهیم با سطح انتزاع بالا را با استفاده از یادگیری چند لایه از پایین به بالا بسازیم به تصویر 3 دقت کنید. این تصویر مفهوم لایه لایه بودن مراحل یادگیری را در بازشناسی چهره انسان به خوبی نمایش می دهد.
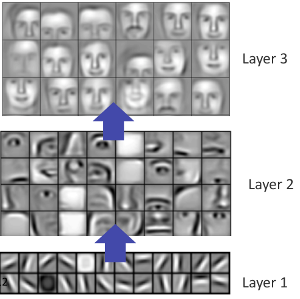
تصویر 3 – یادگیری لایه لایه