در بازشناسی چهره انسان شما با دیدن تصویر یک فرد باید بگویید که این تصویر مربوط به کدام یک از افرادی است که قبلا دیدهاید. این مسئله دو بخش دارد:
- بخش آموزش: در این بخش شما افرادی را که میخواهید سیستم بشناسد با تصویر به سیستم میدهید.
- بخش آزمایش: در این بخش اگر تصویری از یکی از افرادی که میشناسد را به سیستم بدهیم، سیستم باید او را به درستی به یاد بیاورد.
این مسئله کاربردهای زیادی دارد. برای مثال اگر تعداد افرادی که آموزش میدهیم یک فرد باشد، میتوان از این سیستم به عنوان جایگزین رمز عبور برای رایانه استفاده کرد.
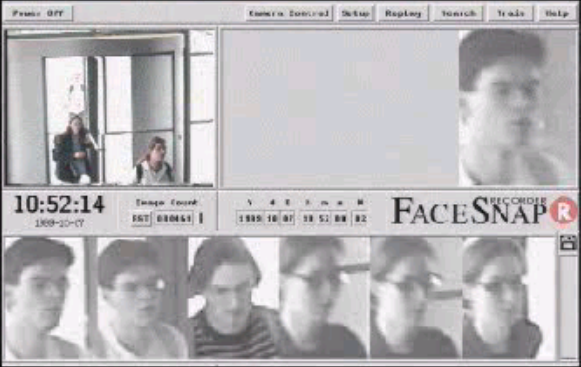
اگر برای مثال تصویر چهره مجرمها را به سامانه آموزش دهیم، میتوان از دوربینهای سطح شهر برای پیدا کردن مجرمها استفاده کرد.
کارایی تشخیص چهره علاوه بر کاربردهای مرتبط با تعیین و مقایسه هویت نظیر کنترل دسترسی, امور قضایی, صدور مجوزها و مدارک هویتی و نظارت, در زمینه هایی نظیر تعامل انسان و کامپیوتر, واقعیت مجازی بازیابی اطلاعات از پایگاه های داده, مالتی مدیا و سرگرمی های کامپیوتری به اثبات رسیده است.
یک سیستم تشخیص چهره متداول شامل سه مرحله زیر است:
- کشف چهره (Face Detection)
- استخراج الگوها (Feature Extraction)
- تشخیص چهره (Face Recognition)
چالش های پیش رو
شرایط ثبت تصویر نظیر وضعیت چهره نسبت به دوربین, نورپردازی, حالتهای چهره و تعداد پیکسلها در ناحیه چهره و همچنین روند پیر شدن انسان می تواند تغییرات زیادی را بر چهره انسان تحمیل کند. تغییرات دیگری هم ممکن است از طریق قیافه, پوشش هایی نظیر کلاه یا عینک آفتابی و موی صورت به وجود آید. همچنین افزایش سن, در برخی افراد باعث افزایش یا کاهش وزن می شود.
الگوریتم ها
الگوریتمهای مختلفی برای تشخیص چهره وجود دارند که معمول ترین آنها عبارتند از: PCA – ICA – LFDA – EBGM – SVM – …
الگوریتمی که در این پست مورد بررسی واقع می گردد برای هدف برنامه PCA خواهد بود.
کارهای مرتبط
تا قبل از ارائه ی PCA برای تشخیص چهره, بیشتر کارها روی شناسایی ویژگی های بخشهای صورت مانند چشمها, بینی, دهان و … و تعریف روابط بین این اعضا متمرکز بود. اما تحقیقات روی قدرت انسان در تشخیص چهره نشان داد که ویژگی های اعضای منفرد صورت و ارتباطات لحظه ای بین آنها برای شناخت مناسب چهره کافی نیست.
در سال 1966 Bledsoe اولین کسی بود که یک روش نیمه اتوماتیک برای تشخیص چهره ارائه کرد. در این روش چهره ها بر اساس ویژگی هایی که به وسیله ی انسان علامت زده شده بود دسته بندی می شدند. اندکی بعد با کارهای انجام شده در آزمایشگاههای Bell, یک بردار با بیش از 21 ویژگی (مانند عرض دهان, ضخامت لبها و …) تو سعه داده شد. ویژگی های انتخاب شده عمدتاً حاصل ارزیابی های ذهن انسان بودند و پیاده سازی آنها کار مشکلی بود.
در سال 1989, Kirby و Sirovich یک روش جبری برای محاسبه ساده ی eigenface ها ارائه کردند.
در سال 1991 , [2] Turk و Pentland اثبات کردند که خطای مانده هنگام کدینگ eigenface ها می تواند برای دو منظوراستفاده شود:
- تشخیص وجود چهره در یک عکس
- تعیین محل تقریبی چهره در عکس
این دو نفر نشان دادند که با ترکیب دو مورد بالا, تشخیص بلادرنگ چهره ممکن است. این مطلب جرقه ی یک انفجار در تحقیقات تشخیص چهره بود. بعد از ارائه ی این روش مقالات زیادی بر مبنای آن به رشته ی تحریر درآمده که در ادامه به برخی از آنها اشاره میکنیم :
در مقاله ای از [3] Rajkiran Gottumukkal, Vijayan K.Asari روشی به نام Modular PCA ارائه شده است. با مقایسه ی این روش با روش PCA متداول, مشخص می شود که این روش با وجود تغییرات زیادی در جهت تابش نور وحالت چهره, نرخ بازشناسی بیشتری نسبت به PCA دارد. در این روش عکسها به چند قسمت کوچکتر تقسیم می شوند و PCA روی هرکدام از این قطعات به طور جداگانه اعمال می شود. این موضوع باعث می شود که تغییرات چهره از جمله تغییر در جهت تابش نور و حالت چهره, باعث تغییر ویژگی های موضعی چهره یک فرد نشود.
در مقاله ای از [4] Trupti M. Kodinariya با ترکیب الگوریتم PCA با چند الگوریتم دیگر یک روش ترکیبی ارائه شده است.
در این مقاله سیستم تشخیص چهره در دو حالت کار می کند : تمرین و دسته بندی :
حالت تمرین شامل نرمال سازی و استخراج ویژگی از تصاویر با استفاده از الگوریتم PCA, ICA می باشد. . سپس ویژگی های استخراج شده, با استفاده از BPNN ها (back propagation neural network) تمرین داده می شوند تا فضای ویژگی ها به کلاسهای متفاوت دسته بندی شوند.
در حالت دسته بندی,عکسهای جدید به نتایج حاصل از حالت تمرین اضافه می شوند. یک روش ترکیب کننده, روی نتایج بخش تمرین اعمال می شوند تاعکسهای جدید برحسب کلاسهای ایجاد شده دسته بندی شوند.
در مقاله ای از احمد محمودی, روشی با نام PCA چند لایه[5] ارائه شده است. در این روش برای محاسبه ی مولفه های اصلی از یک شبکه عصبی خطی استفاده شده است, که علاوه بر کاهش حجم مورد نیاز برای محاسبات, طراحی سخت افزار آن بسیارساده تر خواهد بود. همچنین با توجه به قابلیت های شبکه عصبی در پردازش موازی, سرعت انجام محاسبات افزایش چشم گیری داشته است.
منظور از واژه ی چند لایه در این پست این است که برای بازشناخت چهره ی یک فرد, ابتدا چند چهره که بیشترین شباهت به این چهره را دارند استخراج شده, آنگاه در مرحله ی بعد فرایند پیشنهادی در بین چهره هایی که بیشترین امتیاز شباهت را دارا میباشند ادامه داده شود. با توجه به این که دامنه ی جستجو محدودتر شده, انتظار می رود که نتایج بدست آمده دقیق تر باشد.
در مقاله ای از داود ساریخانی, روشی با استفاده از الگوریتم های PCA, LDA و شبکه های عصبی [6] پیشنهاد شده است.روش ارایه شده دارای چهارقسمت پردازشی زیراست:
- بخش پیش پردازش شامل یکنواخت سازی هیستوگرام و نرمالیزه کردن تصاویر
- بخش کاهش بعد فضا به کمک PCA
- استخراج ویژگیها با استفاده از LDA برای جداسازی کلاس ها و تفکیک پذیری چهره ها
- استفاده از شبکه عصبی به منظور طبقه بندی چهره ها و اعلام هویت چهره
الگوریتم Principal Component Analysis) PCA):
این روش در سال 1991 توسط Turk و Pentland پیشنهاد شد که از تحلیل المانهای اصلی یا همان PCA برای کاهش بعد استفاده کرده تا بتواند زیرفضایی با بردارهای متعامد پیدا کند که در آن زیرفضا پراکندگی داده ها را به بهترین حالت نشان دهد. این زیرفضا را هنگامی که بر روی داده های چهره اعمال شوند، فضای چهره میگویند. پس از مشخص شدن بردارها تمامی تصاویر به این زیر فضا منتقل میشوند تا وزنهایی که بیانگر تصویر در آن زیرفضا هستند بدست آیند. با مقایسه شباهت وزنهای موجود با وزن تصویر جدیدی که به این زیر فضا منتقل شده میتوان تصویر ورودی را شناسایی کرد.
با نمایش بردار ی چهره ی انسان که توسط کنار هم قرار دادن سطرهای ماتریس تصو یر حاصل می شود می توان چهره ی انسان را برداری در فضایی با ابعاد بالا در نظر گرفت. با توجه به خصوصیات مشابه چهره ها، می توان نتیجه گرفت که بردار چهره ها در ز یرفضایی با ابعاد پایین تر واقع شده اند. با نگاشت چهره به این زیر فضا می توان تصاو یر پایه ی جدیدی به دست آورد که هر چهره با کمک این بر دارهای پایه توصیف می شود. در واقع هر چهره ترکیب خطی این تصاو یر پایه می باشد .ضرایب این ترکیب خطی به عنوان بردار خصیصه مورد استفاده قرار می گیرند.
در این روش یک تصویر با ابعاد n*m به یک بردار با nm مولفه تبدیل می شود. یعنی می توان عکس را به صورت نقطه ای در فضای nm بعدی تصور کرد.
هدف PCA یافتن بردارهایی است که به بهتر ین نحو ممکن کار شناسایی ز یر فضا را انجام دهند. این بردارها فضای چهره را تعریف می کنند. از آن جایی که این بردارها، بردار ویژه ی ماتر یس همبستگی مربوط به تصاویر چهره می باشند و همچنین به دلیل شباهت به چهره یانسان، آن ها را eigenface می نامند.
محاسبه ی eigenface ها
اگر مجموعه ی عکس های ورودی را ماتریسهای
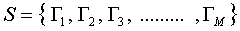
در نظر بگیریم, میانگین چهره ها به صورت زیر محاسبه می شود:
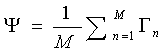
البته همان طور که در بخش قبل گفته شد در این روش یک تصویر با ابعاد n*m به یک بردار با nm مولفه تبدیل می شود. یعنی ما یک عکس را به صورت یک بردار سطری یا ستونی با nm مولفه در نظر می گیریم. تمامی فرمول های ذکر شده در این الگوریتم با این فرض است که ماتریس تصویر را به صورت یک بردار ستونی درنظر گرفته ایم.

تفاوت هر تصویر از میانگین به صورت زیر محاسبه می شود:
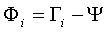
بردار Uk به نحوی انتخاب می شود که مقدار λk ماکزیمم شود:
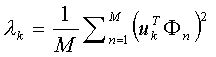
البته با فرض زیر:
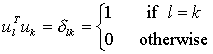
بردارهای Uk و λk به ترتیب بردارهای ویژه و مقادیر ویژه ی ماتریس همبستگی می باشند.ماتریس همبستگی از رابطه ی زیر محاسبه می شود :
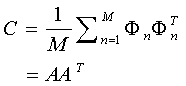
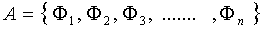
یعنی می توان با استفاده از ماتریس کوواریانس نیز به بردار و مقدار ویژه رسید.
بردار U همان بردار eigenface میباشد. نمونه ای از آنرا در تصویر زیر مشاهده می کنید :

همان طور که مشاهده می کنید, بردار ویژه در واقع شامل عکسهایی با همان ابعاد عکس های ورودی می باشد که شبیه به شبح هستند.
بخش بازشناسی چهره
برای تشخیص اینکه یک عکس جدید مربوط به کدام یک از عکسهایی که سیستم با آن تمرین داده شده است, می باشد باید تمام عکسهایی که سیستم با آن تمرین داده شده است و همچنین عکس جدید را به فضای چهره نگاشت کنیم.
اگر هر یک از این عکسها را Γ بنامیم آنگاه طبق فرمول زیر می توان عکس را به فضای چهره نگاشت کرد:
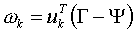
سپس بردار وزنها را تشکیل می دهیم:
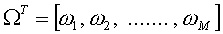
حالا می توانیم تعیین کنیم که عکس ورودی متعلق به کدام کلاس است. یکی از راههایی که برای این کار وجود دارد این است که بردار وزنهای عکس ورودی را با بردار وزنهای عکسهایی که قبلاً به سیستم آموزش داده شده بودند مقایسه کنیم. برای این کار می توانیم از فاصله ی اقلیدسی مانند زیر استفاده کنیم :
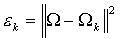
یعنی ما به تعداد عکسهایی که سیستم با آن تمرین داده شده اند, ϵ داریم.
اگر مقدار ϵ از یک مقدار از پیش تعیین شده کمتر بود, آنگاه تصویر ورودی یک تصویر شناخته شده است.اگر بیشتر بود و از یک مقدار دوم کمتر بود آنگاه تصویر ورودی یک شخص ناشناس است. اما اگر از هر دو مقدار بزرگتر بود تصویر ورودی چهره نیست!
اما پس از تشخیص اینکه تصویر ورودی یک تصویر شناخته شده است, برای اینکه تشخیص بدهیم که این عکس مربوط به چه کسی است باید مقدار ϵ ها را با هم مقایسه کنیم. بدیهی است که عکس ورودی مربوط به عکسی است که فاصله ی آنها (ϵ) کمتر از سایر عکسها باشد.
بهبود محاسبه ی بردارهای ویژه ی ماتریس کوواریانس
فرض کنید n عکس با اندازه ی x∗y داریم. پس از تغییر شکل عکسها به یک بردار, اندازه ی ماتریس شامل بردارها, n∗xy خواهد بود. پس از بدست آوردن اختلاف هر عکس با میانگین عکس ها, بردار A با اندازه ی n∗xy به وجود می آید.
طبق رابطه ی کوواریانس, اندازه ی ماتریس کوواریانس xy∗xy خواهد بود. برای درک این اندازه, فرض کنید که ابعاد عکس ورودی, 100×100 پیکسل باشد. طبق محاسبات بالا اندازه ی ماتریس کوواریانس 10000×10000 خواهد بود. یعنی باید 100 میلیون نقطه را ذخیره کرد که این کار به حدود 0.8 گیگا بایت حافظه نیاز دارد! درضمن محاسبه ی یک ماتریس با این حجم به زمان زیادی نیز نیاز دارد.
برای حل این مشکل از یک قضیه ی ریاضی استفاده می کنیم. این قضیه بیان می کند که بردارهای ویژه ی ماتریس A∗AT با بردارهای ویژه ی ماتریس AT∗A یکسان است. یعنی ما می توانیم از ماتریس AT∗A استفاده کنیم که یک ماتریس n∗n (n تعداد عکسهای ورودی است) می باشد و حجم محاسبات آن به شدت کمتر از یک ماتریس xy∗xy می باشد.
آزمایشها
برای آزمایش این سیستم نیاز به یک مجموعه عکس استاندارد داریم. برای این کار از مجموعه داده ی AT&T متعلق به دانشگاه کمبریج استفاده می کنیم. این مجموعه عکس شامل عکسهای 40 فرد و از هر فرد 10 عکس مختلف می باشد. یعنی در مجموع شامل 400 عکس می باشد.
آزمایش اول: کد مربوط به این بخش را می توانید از اینجا دریافت کنید.
برای آزمایش 25 عکس از این مجموعه انتخاب می کنیم:

همانطور که توضیح داده شد یکی از مراحل الگوریتم محاسبه ی میانگین تصاویر وروری است. میانگین 25 تصویر بالا را در عکس زیر می بینید:

بردارهای ویژه (eigenface) ی بدست آمده از عکسهای بالا را در تصویر زیر می بینید:

برای آزمایش نرخ تشخیص چهره, 25 عکس جدید که مربوط به همان افرادی می شدند که در بالا مشاهده کردید به سیستم داده شد. که حدود 50 درصد از آنها به درستی شناسایی شدند که با توجه به اینکه از هر فرد تنها یک عکس برای تمرین به سیستم داده شده بود, قابل قبول به نظر می رسد.
اما یکی از کارهایی که باعث می شود نرخ تشخیص چهره افزایش پیدا کند, مطمئناً تمرین دادن سیستم با عکس های بیشتر است. به این معنی که ما از هر فرد, چند عکس مختلف به سیستم بدهیم و سیستم فضای چهره را با استفاده از این عکس ها ایجاد کند. کد پیاده سازی شده برای این بخش را می توانید از اینجا دریافت نمایید.
برای آزمایش نرخ تشخیص چهره با این روش, 6 عکس از 25 مجموعه عکس (هر مجموعه متعلق به چهره ی یک فرد) از مجموعه داده ی AT&T, یعنی در مجموع 150 عکس, به سیستم داده شد, تا سیستم با آنها تمرین داده شود. سپس 25 عکس مربوط به همان افرادی که سیستم با عکس آنها تمرین داده شده بود, برای تشخیص به سیستم داده شد که 84 درصد از آنها به درستی شناسایی شدند. مشاهده می شود که نرخ تشخیص چهره نسبت به زمانی که از هر فرد فقط یک عکس برای تمرین به سیستم داده شده بود, بیش از 30 درصد افزایش یافته است.
روش PCA چند لایه
این روش در مقاله ی [5] ارائه شده است. این روش به این صورت است که پس از این که سیستم با چند عکس تمرین داده شد, عکسها بر اساس میزان نزدیکی به تصویر ورودی مرتب می شوند. تعدادی از شبیه ترین عکس ها به عکس ورودی انتخاب می شوند و سیستم دوباره و با این تعداد عکس انتخاب شده تمرین داده می شود. این روند می تواند چند مرحله ی دیگر تکرار شود. با توجه به اینکه در هر مرحله دامنه ی جستجو محدود تر می شود, انتظار می رود که نتایج دقیق تری بدست آید. هر مرحله از این الگوریتم را یک لایه می نامند, به همین دلیل این روش, pca چند لایه نامیده شده است.
کد پیاده سازی شده مربوط به این الگوریتم را می توانید از اینجا دریافت کنید. برای آزمایش نرخ تشخیص چهره با این روش,آزمایشی مشابه آزمایش اول, انجام شد و حدود 55 درصد از تصاویر ورودی به درستی شناسایی شدند که نشانگر بهبود 5 درصدی نسبت به الگوریتم pca معمولی می باشد.
روش Modular PCA
این روش در مقاله ی [9] ارائه شده است. روش PCA معمولی در مقابل تغییرات حالت قرار گرفتن چهره در تصویر و تغییرات میزان نور در تصویر, بازده خوبی ندارد. چون در این روش مشخصات عمومی چهره, در قالب مجموعه ای از وزن ها (بردار وزن ها) توصیف می شود. تک تک این وزن ها وابسته به تمام نواحی چهره می باشند. بنابراین با تغییر حالت چهره و نورپردازی, حتی در قسمتی از تصویر, تمام وزن های این بردار دچار تغییر می شوند.
روش MudularPca سعی در رفع این مشکل دارد. در این روش یک عکس به چند قسمت کوچکتر تقسیم می شود و الگوریتم PCA روی این عکس ها اعمال می شود و بردار وزن ها برای هر قطعه به صورت جداگانه محاسبه می شود. با این عمل(تقسیم تصویر به چند تکه), تغییر در قسمتی از تصویر تنها بردار ویژگی آن قسمت از تصویر را تغییر می دهد و بردارهای مربوط به سایر قطعات بدون تغییر باقی می مانند. هنگام تشخیص چهره, هر قطعه از عکس ورودی با قطعه ی متناظر در تصاویری که سیستم با آنها تمرین داده شده است مقایسه می شود و به تعداد قطعات, فاصله محاسبه می شود. تصویری که مجموع فواصل قطعات آن با قطعات عکس ورودی کمتر از سایر تصاویر باشد, به عنوان تصویر مشابه با تصویر ورودی در نظر گرفته می شود.
کد پیاده سازی شده ی این الگوریتم را می توانید از اینجا دریافت کنید. برای آزمایش این روش, آزمایشی مشابه آزمایش اول انجام شد, اما تغییر محسوسی در نتایج بدست نیامد.
نحوه ی استفاده از کدها در گیت هاب قرار داده شده است.
کارهای آینده
برای بهبود نتایج حاصل از PCA معمولی که در بخش کارهای مرتبط شرح داده شد, کارهای زیادی انجام شده است و مقالات زیاد به چاپ رسیده است. تعدادی از این روش ها در بخش آزمایش ها شرح داده شد و کد مربوط به آنها پیاده سازی شد. در این بخش چند نمونه از کارهای انجام شده ی دیگر را بدون پیاده سازی به طور مختصر شرح می دهیم :
برای مثال در مقاله ی [10] فرمولهای مختلف فاصله, برای بدست آوردن فاصله ی تصویر ورودی و تصاویر موجود در سیستم استفاده شده است و نرخ تشخیص چهره ی آن ها با هم مقایسه شده است. در این مقاله از فاصله های euclidian distance, city block distance, angle distance, mahalanobis distance و یک بار هم از مجموع این چهار فاصله استفاده شده است و این نتیجه بدست آمده است که استفاده از مجموع این چهار فاصله نتیجه ی بهتری می دهد.
همچنین در برخی از مقاله ها قبل از اعمال الگوریتم PCA روی تصاویر, پیش پردازش هایی روی تصاویر انجام می شود. برای مثال ابتدا الگوریتم های کاهش نویز روی تصاویر اعمال می شود و سپس الگوریتم PCA روی تصاویر حاصل اعمال می شود.
همانطور که در بخش های مختلف گفته شد, پس از ارائه ی الگوریتم PCA کارهای زیادی برای بهبود عملکرد این الگوریتم انجام شده است که بررسی همه ی آنها در این پست نمی گنجد.
مراجع
[1].Moon, P.J. Phillips, Computational and Performance aspects of PCA-based Face Recognition Algorithms, Perception,
- 30 Vol.
[2].M. Turk, A. Pentland, Eigenfaces for Recognition, Journal of Cognitive Neurosicence, Vol. 3, No. 1, 1991
[3]. Gottumukkal, Rajkiran and Asari, Vijayan K.. An improved face recognition technique based on modular PCA approach. . In Pattern Recognition Letters, (25) 4: 429-436, Year 2004 .
[4] . Trupti M. Kodinariya: Hybrid Approach to Face Recognition System using Principle component and Independent component with score based fusion process. CoRR abs/1401.0395 (2014)
[5]. محمودی ازناوه، احمد، فرح ترکمنی آذر، و آزاده منصوری، 1385، بازشناخت چهره با استفاده از PCA چند لایه و شبکه ی عصبی خطی، دوازدهمین کنفرانس سالانه انجمن کامپیوتر ایران، تهران، دانشگاه شهید بهشتی، http://www.civilica.com/Paper-ACCSI12-ACCSI12_185.htm
[6]. ساریخانی مقدم، داود، 1390، تشخیص چهره به کمک الگوریتم های PCA LDA و شبکه های عصبی، دومین همایش سراسری فن آوری اطلاعات و ارتباطات، ملایر، دانشگاه آزاد اسلامی واحد ملایر، http://www.civilica.com/Paper-NCICT02-NCICT02_037.html
[7].A. Pentland, B. Moghaddam, T. Starner, View-Based and Modular Eigenspaces for Face Recognition, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 21-23 June 1994, Seattle, Washington, USA
[8]. http://www.pages.drexel.edu/~sis26/Eigenface%20Tutorial.htm
[9]. Rajkiran Gottumukkal, Vijayan K.Asari. (2003). An improved face recognition technique based on modular PCA approach. ELSEVIER.
[10]. Kuldeep Singh Sodhi, Madan Lal. (2013). Comparative Analysis of PCA-based Face Recognition System using different Distance Classifiers. International Journal of Application or Innovation in Engineering & Management (IJAIEM).
درووووووود بر شما
سلامت باشید
عالی بود خیلی متشکرم.
خواهش می کنم دوست عزیز
با عرض سلام مقاله در مورد تشخیص چهره میخوام اگ امکان داره ب ایمیلم برفرستید متشگر میشم از تون سپاسگزارم
سلام
چند مورد مقاله می خواهید عزیز؟
نوع روش های استفاده شده پایه آن مهم است یا خیر؟