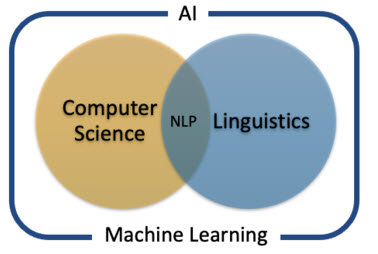
پردازش زبان طبیعی شاخه ای از هوش مصنوعی است که با ارتباطات سر و کار دارد: چگونه می توان کامپیوتر مانند یک فرد برای درک، پردازش و تولید زبان برنامه ریزی کرد؟ در حالی که این اصطلاح در ابتدا به توانایی سیستم برای خواندن اشاره داشت، از آن زمان به یک بخش محاوره ای برای همه بخش های زبان شناسی محاسباتی تبدیل شد. زیرمجموعه ها شامل تولید زبان طبیعی، توانایی رایانه در ایجاد ارتباطات برای خود و درک زبان طبیعی، توانایی درک عامیانه، تلفظ های اشتباه، غلط املایی و سایر انواع زبان است. می توان جایگاه پردازش زبان طبیعی را در شکل زیر مشاهده کرد.
پردازش زبان طبیعی از طریق یادگیری ماشین کار می کند. سیستم های یادگیری ماشینی مانند هر شکل دیگری از داده ها کلمات و روش های جمع آوری آن ها را ذخیره می کنند. عبارات، جملات و بعضی اوقات کل کتاب ها به موتورهای یادگیری ماشین منتقل می شوند که براساس قوانین دستوری، عادات زبانی زندگی واقعی افراد یا هر دو، پردازش می شوند. سپس رایانه با استفاده از این داده ها، الگوهایی را پیدا می کند و موارد بعدی را برون ریزی می کند. برای مثال از نرم افزار ترجمه استفاده می شود: در فرانسه، “من به پارک می روم” معادل “Je vais au parc” است، بنابراین یادگیری ماشین پیش بینی می کند که “من به فروشگاه خواهم رفت” نیز با “Je vais au” آغاز می شود”. تمام آن چه که رایانه پس از آن نیاز دارد کلمه “ذخیره” است. ترجمه ماشینی یکی از کاربردهای بهتر پردازش زبان طبیعی است، اما بیشترین استفاده را نمی کند و بیشتری استفاده از آن جستجو است. هر وقت در Google یا Bing یک واژه یا چیزی جستجو می شود، داده ها در سیستم تغذیه می شوند. وقتی روی یک نتیجه جستجو کلیک می شود، سیستم این را تصدیق درست بودن نتیجه ای می داند و از این اطلاعات برای جستجوی بهتر در آینده استفاده می کند.
بسته به پیچیده بودن متن و متغیرهایی لازم است استخراج گردد، پردازش زبان طبیعی می تواند نسبتا آسان یا دشوار باشد. به عنوان مثال، استخراج علائم از متن یک شکایت با استفاده از روش های ساده، نسبتا آسان است، زیرا شکایات اصلی عبارات کوتاهی هستند که دلیل تشریح مراجعه بیمار را بیان می کنند. استخراج تشخیص از شکایات اصلی امکان پذیر نیست، زیرا اطلاعات در یک شکایت اصلی قبل از مراجعه بیمار حتی به پزشک ثبت می شود. هنگامی که بیمار توسط پزشک معاینه شد، ممکن است تشخیص بیمار در یک گزارش دیکته شده ثبت شود. استخراج اطلاعات از گزارش های دیکته شده بسیار دشوارتر است، زیرا یک گزارش، یک داستان پیچیده در مورد بیمار را بیان می کند که شامل مراجعه به زمان و نفی علائمی است که در شکایات اصلی وجود ندارد. انواع مختلفی از فناوری ها در پردازش زبان طبیعی استفاده می شود. به طور کلی، انتخاب فناوری به ویژگی های زبانی متن بستگی دارد. برخی از خصوصیات زبانی وجود دارد که پردازش آن ها چنان دشوار است که روش های موثر پردازش زبان طبیعی برای آن ها وجود ندارد. به عنوان مثال، تعداد کمی از سیستم های پردازش زبان طبیعی می توانند اطلاعاتی را که با استفاده از استعاره منتقل می شود، با دقت استخراج کنند.
مغز انسان به طور طبیعی برای زبان و گفتگو، با فکر و تمرکز و آموزش واژه ها، کار می کند. اما، برنامه های رایانه ای این گونه نیستند. آموزش رایانه برای پردازش زبان انسان چالش برانگیز است. مشکلات انتزاعی سطح بالایی در پردازش زبان وجود دارد، مانند این که چگونه می توان فهمید وقتی شخصی از شوخی استفاده می کند. اما پیمایش قوانین سطح پایین زبان نیز ممکن است دشوار باشد. به عنوان مثال، برخی از واژه ها چند معنی دارند، به ویژه هنگامی که به صورت شاعرانه استفاده می شوند. چگونه به یک کامپیوتر می توان گفت که تفاوت کتاب و رزرو وقت را بداند؟ بین رهبری و سرب؟ بین گل رز و گل سرخ؟ این ها چالشهایی است که برنامه نویسان پردازش زبان طبیعی باید بر آن ها غلبه کنند. پردازش زبان طبیعی برای پردازش وظایف به دو تکنیک اصلی متکی است: تکنیک های نحو و معنایی. تکنیک های نحو برنامه های رایانه ای را برای تفسیر زبان انسان بر اساس قوانین دستوری نحو – ترتیب کلمات و عبارات آموزش می دهند. برای این تکنیک، برنامه ها با استفاده از الگوریتم هایی قواعد دستور زبان را در داده ها (کلمات) به کار می برند تا معنی بگیرند. برخی از توابع معمول شامل تقسیم بندی ریخت شناختی (تقسیم کلمات به واحدهای مجزا به نام اصطلاحات)، تقسیم بندی کلمات (تقسیم یک قسمت بزرگ از متن به بخش های کوچک تر) و ریشه گذاری (برش یک کلمه خلاصه شده تا شکل ریشه آن برای تجزیه و تحلیل آسان تر) در این بخش قرار می گیرد. به این ترتیب، برنامه های رایانه ای می توانند با استفاده از الگوریتم ها به بهترین نحو رمزگشایی گفتار انسانی را به صورت مناسب انجام دهند. تکنیک دیگر پردازش زبان طبیعی و مسلما دشوارتر، مربوط به معناشناسی است. تحلیل معنایی همه چیز درمورد معنایی است که از طریق یک زبان بر اساس تفسیر کلمات و ساختار جمله منتقل می شود. توابع معنایی متداول شامل شناخت موجودیت نامگذاری شده است که توسط آن برنامه ها کلمات شناخته شده را به مجموعه های سازمان یافته مانند اسامی گروه بندی می کنند. ابهام زدایی از کلمه (استفاده از زمینه برای فرض معنی) و ایجاد زبان طبیعی (که می خواهد با بررسی متقابل اطلاعات در پایگاه های داده اهداف معنایی را تعیین کند)، بخش های دیگر تکنیک های معنایی هستند.