كد: 508
عنوان پروژه: فروش پروژه پياده سازی الگوريتم خوشه بندی C ميانگين (Fuzzy C-Means) با نرم افزار MATLAB
قالب بندی: m
دسته: كامپيوتر – MATLAB
قيمت: 40.000 تومان
قابليت اجرا در نرم افزار: MATLAB
شرح مختصر:
فروش پروژه پياده سازی الگوريتم خوشه بندی C ميانگين (Fuzzy C-Means) با نرم افزار MATLAB
یکی از مهمترین و پرکاربردترین الگوریتم های خوشه بندی، الگوریتم c میانگین می باشد. در این الگوریتم نمونه ها به c خوشه تقسیم می شوند و تعداد c از قبل مشخص شده است. در نسخه فازی این الگوریتم نیز تعداد خوشه ها (c) از قبل مشخص شده است. در الگوریتم خوشه بندی c میانگین فازی تابع هدف بصورت زیر می باشد:
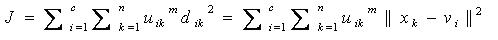
در فرمول فوق m یک عدد حقیقی بزرگتر از 1 است که در اکثر موراد برای m عدد 2 انتخاب می شود. اگر در فرمول فوق m را برابر 1 قرار دهیم تابع هدف خوشه بندی c میانگین (کلاسیک) غیر فازی بدست می آید. در فرمول فوق xk نمونه k ام و vi نماینده یا مرکز خوشه i ام و n تعداد نمونه ها می باشد.uikمیزان تعلق نمونه i ام در خوشه k ام را نشان می دهد. علامت ||*|| میزان تشابه (فاصله) نمونه با (از) مرکز خوشه می باشد که می توان از هر تابعی که بیانگر تشابه نمونه و مرکز خوشه باشد استفاده کرد. از روی uikمی توان یک ماتریس U تعریف کرد که دارای c سطر و n ستون می باشد و مولفه های آن هر مقداری بین 0 تا 1 را می توانند اختیار کنند. اگر تمامی مولفه های ماتریس U بصورت 0 و یا 1 باشند الگوریتم مشابه c میانگین کلاسیک خواهد بود. با اینکه مولفه های ماتریس U می توانند هر مقداری بین 0 تا 1 را اختیار کنند اما مجموع مولفه های هر یک از ستونها باید برابر 1 باشد و داریم:
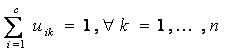
معنای این شرط این است که مجموع تعلق هر نمونه به c خوشه باید برابر 1 باشد. برای بدست آوردن فرمولهای مربوط به uik و vi باید تابع هدف تعریف شده را می نیمم کنیم. با استفاده از شرط فوق و برابر صفر قرار دادن مشتق تابع هدف خواهیم داشت:
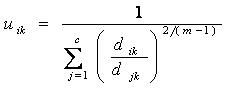
و
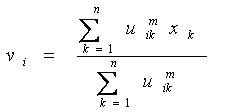
با استفاده از دو فرمول محاسبه شده الگویتم خوشه بندی c میانگین فازی بصورت زیر می باشد.
مراحل الگوریتم:
1.مقدار دهی اولیه برای c، m و U0. خوشه های اولیه حدس زده شوند.
2.مراکز خوشه ها محاسبه شوند (محاسبه viها).
3.محاسبه ماتریس تعلق از روی خوشه های محاسبه شده در 2.
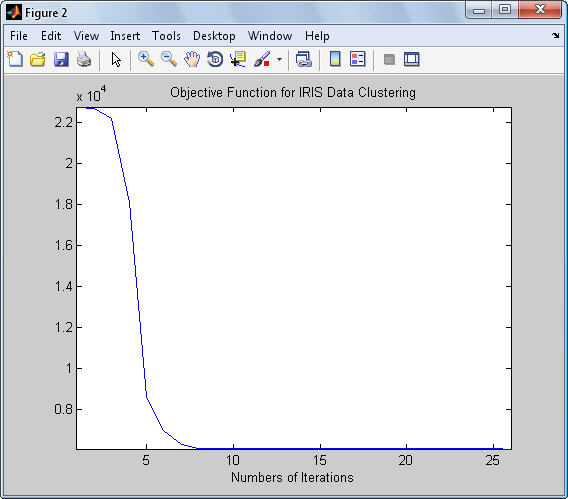
4.اگر ||Ul+1–Ul|| £ e الگوریتم خاتمه می یابد و در غیر اینصورت برو به مرحله 2.
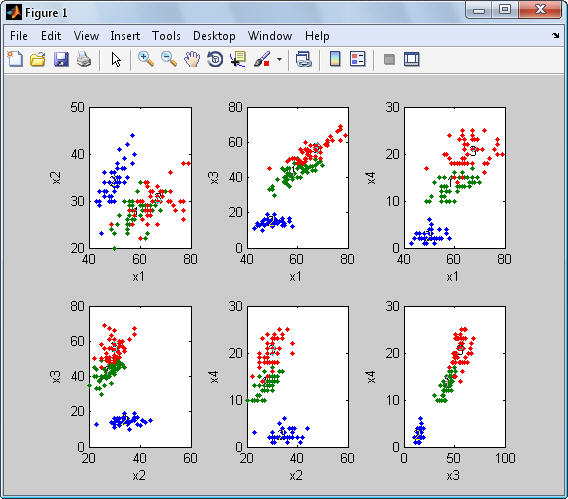
برای مشاهده عملکرد خوشه بندی فازی به مثال زیر توجه کنید. در شکل زیر یک توزیع یک بعدی از نمونه های ورودی را آورده شده است.
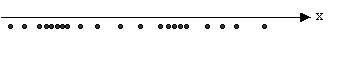
اگر از الگوریتم c میانگین کلاسیک استفاده کنیم داده های فوق به دو خوشه مجزا تقسیم خواهند شد و هر نمونه تنها متعلق به یکی از خوشه ها خواهد بود. بعبارت دیگر تابع تعلق هر نمونه مقدار 0 یا 1 خواهد داشت. نتیجه خوشه بندی کلاسیک مطابق شکل زیر است:
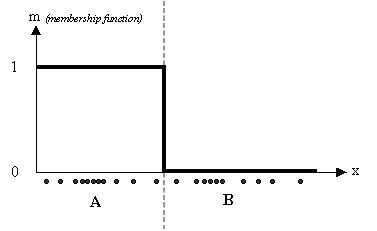
شکل 2 تابع تعلق مربط به خوشه A را نشان می دهد. تابع تعلق خوشه B متمم تابع تعلق A می باشد. همانطور که مشاهده می کنید نمونه های ورودی تنها به یکی از خوشه ها تعلق دارند و بعبارت دیگر ماتریس U بصورت باینری می باشد. حال اگر از خوشه بندی فازی استفاده کنیم خواهیم داشت:
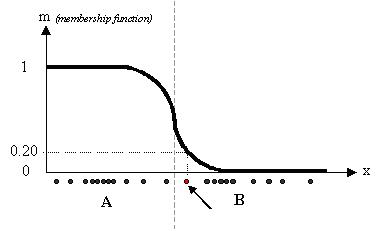
مشاهده می کنید که در این حالت منحنی تابع تعلق هموارتر است و مرز بین خوشه ها بطور قطع و یقین مشخص نشده است. بعنوان مثال نمونه ای که با رنگ قرمز مشخص شده است با درجه تعلق 0.2 به خوشه A و با درجه تعلق 0.8 به خوشه B نسبت داده شده است.
نقاط قوت الگوریتم c میانگین فازی:
نقاط ضعف الگوریتم c میانگین فازی:
اگر معیار تشابه در تابع هدف بر اساس فاصله تعریف شود می توان از تعاریف مختلفی که در مورد فاصله وجود دارد استفاده کرد که در زیر چند نمونه از این توابع آورده شده است:

الگوریتم خوشه بندی cمیانگین برای داده های نویزی:
همانطور که در بالا اشاره شد روش c میانگین حساسیت زیادی به نویز دارد. بهمین روش هایی ابداع شده که کمتر به نویز حساس باشند. یکی از روشهایی که در مورد داده های نویزی مطرح شده این است که یک خوشه برای داده های نویزی در نظر گرفته شود و نمونه هایی که نویز هستند با درجه تعلق زیاد به این خوشه نسبت داده شوند و نمونه هایی که نویز نیستند تعلق کمتری به این خوشه داشته باشند. میزان تعلق بردار ویژگی (نمونه) xk به خوشه نویز بر طبق رابطه زیر تعریف شود:
با این اگر نمونه k ام نویز نباشد سیگمای فرمول فوق باید مقدار بزرگی باشد (نزدیک به 1) و اگر نمونه نویز باشد باید مقدار سیگما نزدیک صفر باشد. بنابر تعریف فوق مجموع درجه تعلقات نمونه ها به c خوشه اولیه کمتر از 1 باید باشد، برخلاف روش c میانگین اولیه که این مجموع باید مساوی 1 شود:
تابع هدفی که برای این خوشه بندی تعریف شده بصورت زیر میباشد:

با مشتق گیری از تابع هدف و با در نظر گرفتن شرط مربوط به مجموع تعلقات نمونه ها به خوشه های اولیه، داریم:

در فرمول بالا δ عدد ثابتی است که برابر است با فاصله مرکز خوشه نویز با تمامی نمونه ها. اگر نمونه k ام نویز باشد جمله دوم فرمول فوق بزرگ می شود و میزان تعلق این نمونه به خوشه ها کم می شود و در نتیج میزان تعلق این نمونه به خوشه نویز افزایش می یابد.
از آنجا که جمله اضافه شده به تابع هدف این الگوریتم به vi بستگی ندارد برای محاسبه مقادیر vi می توان از فرمول ارائه شده برای “الگوريتم C ميانگين فازى” استفاده کرد. با پیدا کردن یک مقدار مناسب برای δ این الگوریتم نتایج بهتری نسبت به روش c میانگین اولیه خواهد داشت.
الگوریتم خوشه بندی c میانگین با استفاده از نمونه های برچسب گذاری شده:
در بعضی از کاربردها علاوه بر نمونه های بدون برچسب، تعداد کمی نمونه بر چسب دار نیز موجود می باشد. در چنین حالتی می توان از روی این نمونه های بر چسب دار حدس های اولیه بهتری برای مراکز خوشه ها بدست آورد. فرض کنید که تعداد نمونه n باشد و M نمونه از این تعداد برچسب دار باشد. در این کاربردها تابع هدف به صورت زیر تعریف می شود:

بردار b نیز بدین صورت تعریف می شود که اگر نمونه k ام برچسب داشته باشد bk =1 و در غیر اینصورت bk =0 است و lik مولفه های ماتریس L می باشند که درجه تعلق نمونه های برچسب دار را نشان می دهند. ضریب α برابر نسبت n به M در نظر گرفته می شود. مشابه قسمتهای قبل با مشتق گرفتن از تابع هدف می توان فرمول های بروز رسانی uik ها را محاسبه کرد و همچنین برای محاسبه مراکز خوشه ها از فرمول ارائه شده در الگوریتم c میانگین استاندارد استفاده می شود. مراحل الگوریتم نیز مشابه مراحل خوشه بندی c میانگین استاندارد می باشد. در این نوع خوشه بندی ها اگر M=n باشد الگوریتم خوشه بندی را با ناظر و اگر M
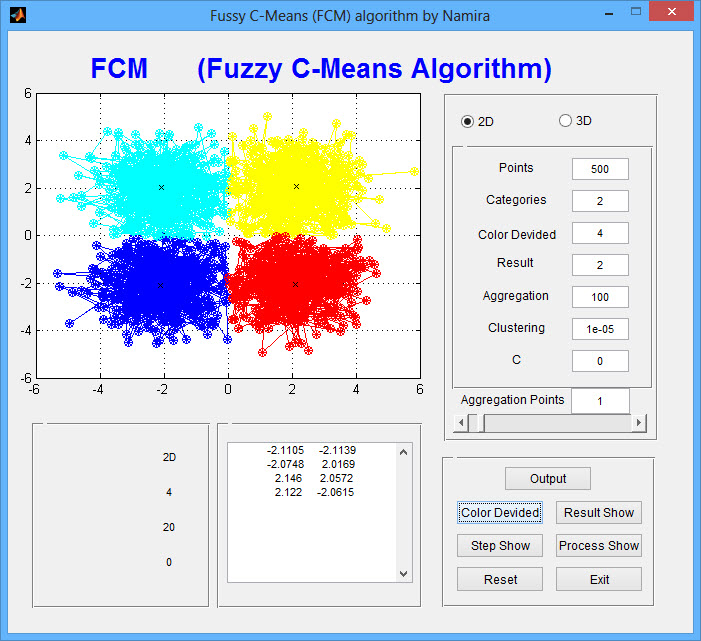
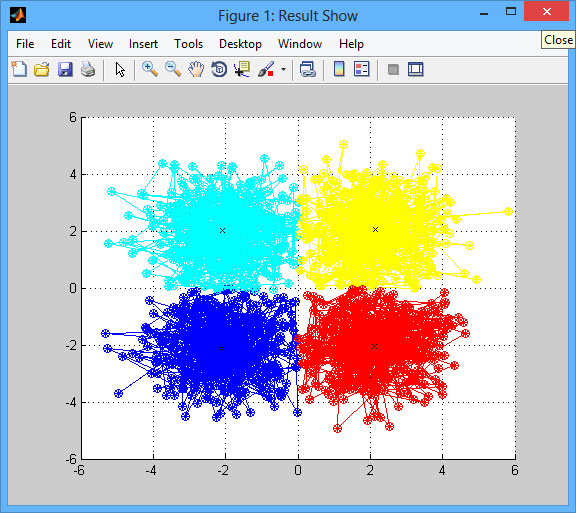
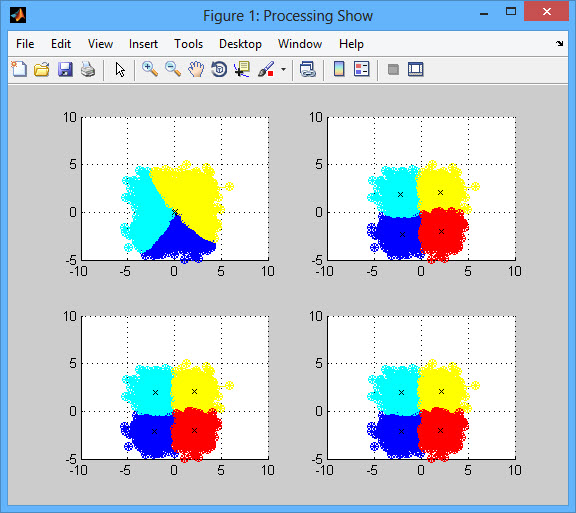
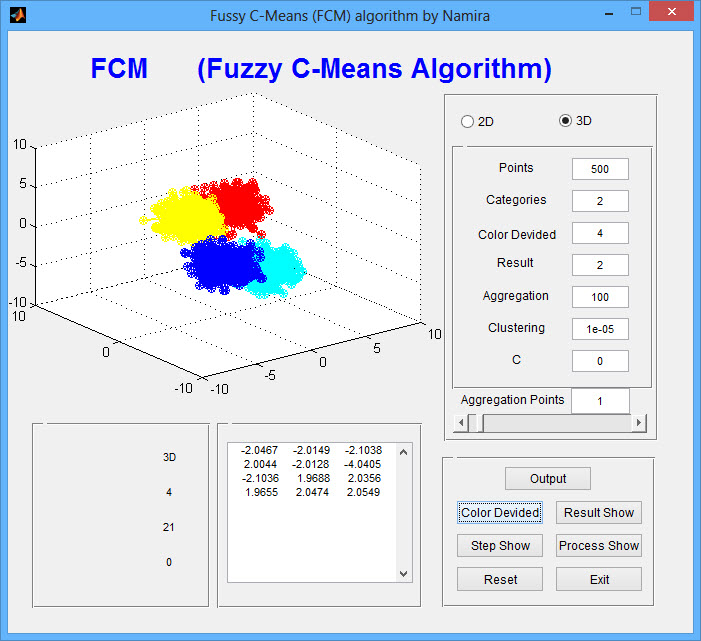
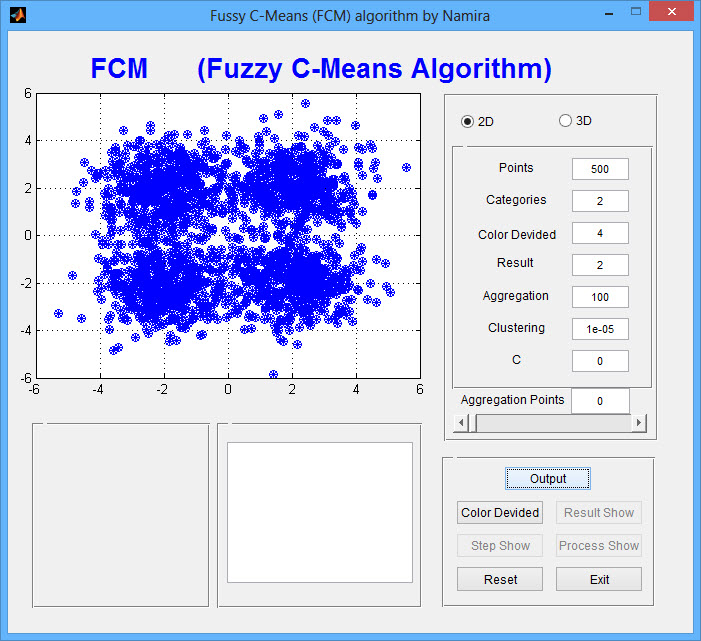
عكس خروجی برنامه
برای خريد اين پروژه با شماره 09360703858
يا آدرس ايميل nn4e@aol.com در تماس باشيد.